 Fraunhofer Institute for Mechanics of Materials IWM
Fraunhofer Institute for Mechanics of Materials IWMMachine learning in materials engineering
Data-driven methods are increasingly finding their way into materials science. Applications range from material design, identification of hidden relations (data mining), and prediction of material’s properties to characterization of microstructures, defects, and damage. By using such methods, predictions can often be greatly improved compared to purely knowledge-based approaches due to their ability to generate highly accurate representations and high fidelity. This is especially true for many problems for which domain knowledge and the models based on it are incomplete.
Conventional machine learning approaches require a large amount of annotated training data for so-called supervised learning. Appropriate methods are characterized by low data efficiency regarding learning compared to humans. Since the data annotation process can often only be performed by experts and is correspondingly expensive, the high demand for such methods in materials science cannot be readily satisfied. In addition, many models have poor transferability across data sets. This lack of generalizability can also be ascribed to sparsely populated training data spaces that contrast large parameter spaces in materials development. The combination of the previously mentioned characteristics makes prediction for new materials difficult.
Within the Meso- and Micromechanics group at the Fraunhofer Institute for Mechanics of Materials IWM, one focal point is dealing with qualifying novel data-driven approaches as well as optimizing these approaches in order to address both of the previously mentioned challenges.
In the course of the last years methods have been adapted which make use of annotated data as well as unannotated data in order to significantly improve predictions compared to supervised learning methods - despite the shortage of annotated data. These methods are subsumed under the term semi-supervised learning methods. Unannotated data can often be collected without much additional effort thanks to the high automation level of industrial plants and analytical methods.
We address the aspect of transferability between domains with models that make use of annotated data from a source domain and unannotated data from a related target domain to achieve good prediction performance in the target domain. This task is called unsupervised domain adaptation. Different process control, modalities, materials, and data sources (e.g., synthetic/simulation data gleaned from experimental data) serve both as source and target domains.
The amount of data required depends on the complexity of the neural network architecture and the concrete problem. By means of intelligent strategies for data augmentation adapted to the problem, as little as ten annotated image instances can be sufficient for training relatively compact networks.
By combining competencies from materials science and computer science, we train customized models for you. In doing so, we take relevant data features into account. Regarding this, we can support you in the entire process chain from the appropriate data collection to the optimal data preparation and model selection as well as training, evaluation and deployment.
- Consultation and/or support during data acquisition
- Appropriate preparation (scaling, normalization, tiling, registration...) of data considering relevant features and model characteristics as well as their optimal data augmentation
- Selection of suitable data for pre-training from our internal material data pool to improve models despite data shortage
- Model selection and implementation
- Classification, segmentation (binary, semantic, instance, panoptic), and regression tasks on pixel data, voxel data, tabular and graph-structured data
- Supervised training of different (pre-trained) models using high-performance hardware for faster results
- Semi-supervised training with additional help of unannotated data for better models in case of low data quantity
- Unsupervised or semi-supervised domain adaptation between related materials, processes or modalities can help to utilize your existing data for new target states without annotating new data.
- Model evaluation and robustness testing

Microstructure quantification of complex phase steels
In two collaborations, we have developed image segmentation models that can identify lath-shaped bainite phases in a complex-phase steel. For this purpose, light and scanning electron microscopic images of etched (for contrasting) surfaces were used. If this task is handled by common knowledge-based models, the prediction quality is comparatively poor. To address this complicated problem, we use convolutional neural networks (FCNN). In the course of the previously mentioned research work, we systematically developed guidelines for the application of different networks depending on the data. Strategies for data augmentation were derived to optimally take data scatter into account. Furthermore, the issue of interpretability of FCNN models was addressed with various visualization methods to increase confidence in the models and to examine them for spurious correlations. The supervised trained models have achieved Intersection over Union (IoU) values of about 80% (this corresponds to accuracies of about 90%) on the test data for different modalities, see Figure 1.
The IoU metric is defined between 0 and 100% and is determined using the number of true positive, false positive and false negative pixels:
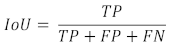

These accuracies correspond to a segmentation quality achieved by metallographers, but offer the advantage that even complicated microstructures can be segmented automatically and reproducibly (more information). However, when supervised trained models were transferred to another etching, these models failed.
In order to address the poor domain transferability of many FCNN architectures, a framework for unsupervised domain adaptation (UDA) has been explored. This problem deals with the case where there is no annotated data, but only input data for target domains, and a good segmentation should be achieved in the target domain. Two different etchings and light microscopic images were used as target domains for this study (see Figure 2).
By using UDA, the mean Intersection over Union (mIoU) was improved over the baseline models (supervised trained on source domain and applied to target domain) from 82.2%, 61.0%, 49.7% to 84.7% (+2.5%), 67.3% (+6.3%), 73.3% (+23.6%) for the three domain transitions, respectively. The comparison between baseline models and UDA is shown in Figures 3-5.
This highlights the potential of these models to develop data-driven methods that can handle different domain distances well, and could significantly reduce the need for annotation (more information).



Image segmentation of material damage (cracks and extrusions)


Another issue within data-driven image processing is the segmentation of fatigue damage [1]. The condition of such damage is highly dependent on the material (Figure 6) and the loading scenario. In addition, image data of damage, due to optical imaging settings, exhibit scatter. Machine learning methods allow automated detection of such damaged locations in diverse materials. Thus, pixel-by-pixel crack and extrusion detection (semantic segmentation) can be performed using neural networks that have already been trained with a versatile data set. Since the training dataset contains a wide variety of crack and extrusion morphologies (see Figure 6) such as protrusions 1) and localized tongue-shaped extrusions 2) in several materials, it is assumed that this method can be transferred to other metallic materials. We combine this automated and generalized method with automated scanning electron microscopy (SEM) to provide efficient damage characterization on sample and component surfaces. For example, in damage detection (Figure 7) in EN 1.4003 ferritic steel, a mean IoU for cracks and extrusions of 0.84 and 0.71 was obtained, respectively. Such damage segmentation has been used, for example, to statistically validate crystal plasticity simulations for short crack growth [2].
[1] Thomas, A.; Durmaz, A. R.; Straub, T.; Eberl, C., Automated quantitative analyses of fatigue induced surface damage by deep learning, Materials 13/15 (2020) Art. 3298, 24 Seiten Link
[2] Natkowski, E.; Durmaz, A.R.; Sonnweber-Ribic, P.; Munstermann, S., Fatigue lifetime prediction with a validated micromechanical short crack model for the ferritic steel EN 1.4003, International Journal of Fatigue 152 (2021) Art. 106418; 15 Seiten
- Gublay, O.; Ackermann, M.; Gramlich, A.; Durmaz, A.R.; Krupp, U., Influence of transformation temperature on the high-cycle fatigue performance of carbide-bearing and carbide-free bainite, Steel Research International, Online first (2023) Art. 2300238, 14 pp. Link
- Goetz, A.; Durmaz, A.R.; Müller, M.; Thomas, A.; Britz, D.; Kerfriden, P.; Eberl, C., Addressing materials’ microstructure diversity using transfer learning, npj Computational Materials 8 (2022) Art. 27; 13 Seiten Link
- Durmaz, A. R.; Müller, M.; Lei, B.; Thomas, A.; Britz, D.; Holm, E. A.; Eberl, C.; Mücklich, F.; Gumbsch, P., A deep learning approach for complex microstructure inference, Nature Communications 12/1 (2021) Art. 6272, 15 Seiten Link
- Natkowski, E.; Durmaz, A.R.; Sonnweber-Ribic, P.; Munstermann, S., Fatigue lifetime prediction with a validated micromechanical short crack model for the ferritic steel EN 1.4003, International Journal of Fatigue 152 (2021) Art. 106418; 15 Seiten Link
- Thomas, A.; Durmaz, A. R.; Straub, T.; Eberl, C., Automated quantitative analyses of fatigue induced surface damage by deep learning, Materials 13/15 (2020) Art. 3298, 24 Seiten Link